Registering Items From External Storage
After you've connected your external storage (AWS, Azure, GCP), you're ready to register files so they can be accessed in a Darwin dataset. This is done through our REST API, so you'll need an API key to continue. Steps to generate your own key are here.
Rate LimitingPlease note that API requests for external storage registration are rate limited which will result in HTTP 429 responses. Please implement appropriate retry and back-off strategies.
If your storage configuration is read-write, please see the section directly below for step-by-step instructions. Otherwise if using read-only, please navigate to the Read-Only Registration section further down.
Stuck? Check out our troubleshooting guide to resolve common errors:
Read-Write Registration
Registering any read-write file involves sending a POST request to the below API endpoint with a payload containing instructions for Darwin on where to access the item:
f"https://darwin.v7labs.com/api/v2/teams/{team_slug}/items/register_existing"The Basics
Below is a Python script covering the simplest case of registering a single image file as a dataset item in a dataset. A breakdown of the function of every field within is available below the script.
import requests
# Define constants
api_key = "your-api-key-here"
team_slug = "your-team-slug-here"
dataset_slug = "your-dataset-slug-here"
storage_name = "your-storage-bucket-name-here"
# Populate request headers
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"ApiKey {api_key}"
}
# Define registration payload
payload = {
"items": [
{
"path": "/",
"type": "image",
"storage_key": "car_folder/car_1.png",
"name": "car_1.png",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}
# Send the request
response = requests.post(
f"https://darwin.v7labs.com/api/v2/teams/{team_slug}/items/register_existing",
headers=headers,
json=payload
)
# Inspect the response for errors
body = response.json()
if response.status_code != 200:
print("request failed", response.text)
elif 'blocked_items' in body and len(body['blocked_items']) > 0:
print("failed to register items:")
for item in body['blocked_items']:
print("\t - ", item)
if len(body['items']) > 0: print("successfully registered items:")
for item in body['items']:
print("\t - ", item)
else:
print("success")-
api_key: Your API key -
team_slug: Your sluggified team name -
dataset_slug: The sluggified name of the dataset to register the file in -
storage_name: The name of your storage integration in your configuration. For example: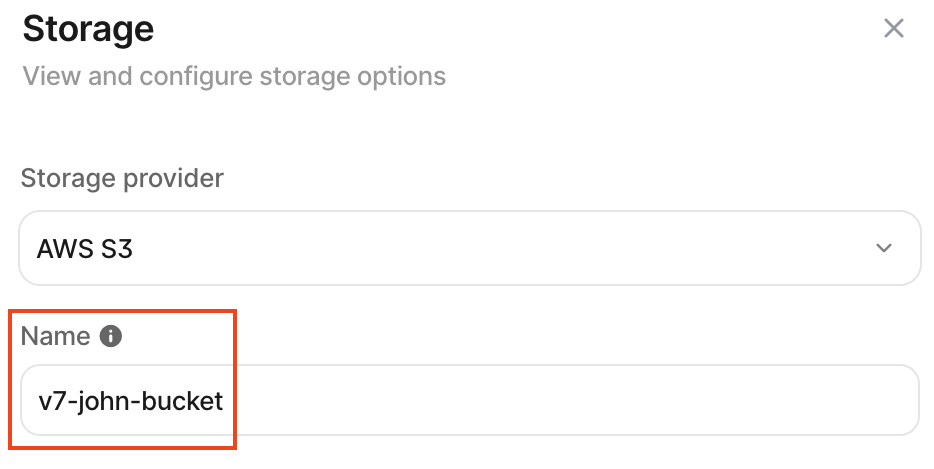
Payload-specific fields & concepts:
items: It's possible to register multiple items in the same request, thereforeitemsis a list of dictionaries where each dictionary corresponds to one dataset item.path: The folder path within the Darwin dataset that this item should be registered attype: The type of file being registered. It can beimage,video,pdfordicom. This instructs us on how to treat the file so it can be viewed correctly. Thetypefield can be omitted if you include the file extension as part of theslots.file_namefield. Please see here for further detailsstorage_key: The exact file path to the file in your external storage. This file path is case sensitive, cannot start with a forward slash, and is entered slightly differently depending on your cloud provider:- For AWS S3, exclude the bucket name. For example if the full path to your file is
s3://example-bucket/darwin/sub_folder/example_image.jpgthen yourstorage_keymust bedarwin/sub_folder/example_image.jpg - For Azure blobs, include the container name. For example if the full path to your file is
https://myaccount.blob.core.windows.net/mycontainer/sub_folder/myblob.jpgthen yourstorage_keymust bemycontainer/sub_folder/myblob.jpg - For GCP Buckets, exclude the bucket name. For example if the full path to your file is
gs://example-bucket/darwin/sub_folder/example_image.jpg, then yourstorage_keymust bedarwin/sub_folder/example_image.jpg
- For AWS S3, exclude the bucket name. For example if the full path to your file is
name: The name of the resulting dataset item as it appears in Darwin. This can be any name you choose, but we strongly recommend giving files the same or similar names to the externally stored files
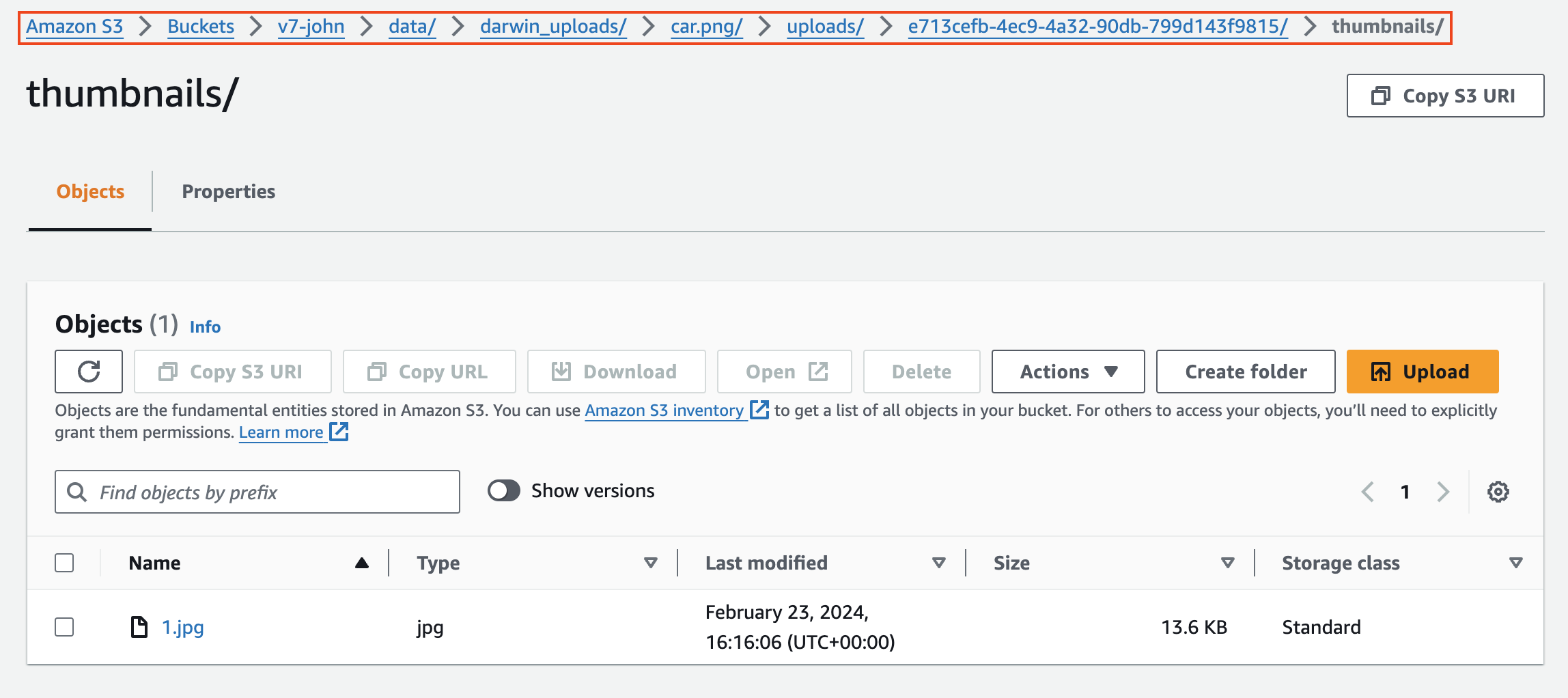
Every image uploaded in read-write will generate a thumbnail in your external storage at the location specified by your configured storage prefix. For example, in an AWS S3 bucket:
Registering Files in Multiple Slots
If you need to display multiple files next to each other simultaneously, you'll need to register them in different slots. Please refer to this article to gain an understanding of the concept of slots.
To register a dataset with multiple slots from external storage, the registration payload changes in structure as follows:
payload = {
"items": [
{
"path": "/",
"slots": [
{
"slot_name": "0",
"type": "image",
"storage_key": "car_folder/car_1.png",
"file_name": "car_1.png",
},
{
"slot_name": "1",
"type": "image",
"storage_key": "car_folder/car_2.png",
"file_name": "car_2.png",
},
{
"slot_name": "3",
"type": "video",
"storage_key": "car_folder/cars.mp4",
"file_name": "cars.mp4",
},
],
"name": "cars",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}Important points are:
- Because the dataset item now contains multiple files, we need to break the item up into separate slots each with a different
slot_name. Slots can be named any string, so long as they are unique for items that need to go into separate slots - Each item in
slotsis given a newfile_namefield. This is distinct from thenamefield which will be the name of the resulting dataset item in Darwin.file_nameshould match the exact file name of the file in that slot (i.e. it should match the last part ofstorage_key). When includingfile_name, if it correctly specifies the extension of the file in external storage, you can omit thetypefield. This is because withouttype, our processing pipeline infers the filetype from the extension offile_name - Only DICOM (
.dcm) slices can be registered within the sameslot_name, resulting in concatenation of those slices. Other file types must occupy their own slot. Please see the section below for further detail - It's possible to register different filetypes in different slots within the same dataset item. For example, above we have 2 slots containing images and a third containing a video
Registering DICOM Files
DICOM (.dcm) files can be either individual slices, or a series of slices. A series of slices as a single .dcm is registered similarly to a video. The only differences are that:
- No
fpsvalue can be passed - The
typeisdicom
payload = {
"items": [
{
"path": "/",
"type": "dicom",
"storage_key": "dicom_folder/my_dicom_series.dcm",
"name": "my_dicom_series.dcm",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}A series of DICOM slices can be uploaded as a sequence by registering them in the same slot_name. For example:
payload = {
"items": [
{
"path": "/",
"slots": [
{
"slot_name": "0",
"type": "dicom",
"storage_key": "dicom_slices/slice_1.dcm",
"file_name": "slice_1.dcm",
},
{
"slot_name": "0",
"type": "dicom",
"storage_key": "dicom_slices/slice_2.dcm",
"file_name": "slice_2.dcm",
},
{
"slot_name": "0",
"type": "dicom",
"storage_key": "dicom_slices/slice_3.dcm",
"file_name": "slice_3.dcm",
},
],
"name": "my_dicom_series",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}
Uploading DICOM Slices as SeriesWhen uploading DICOM slices as a sequence, the order that the slices appears is determined by the following file metadata in order of significance:
- 1:
SeriesNumber- 2:
InstanceNumber- 3:
SliceLocation- 4:
ImagePositionPatient- 5:
FileNameAdditionally, all files passed as slices that contain more than 1 volume will be assigned their own slot.
If you'd prefer to override these behaviours by either:
- 1: Forcing each
.dcmfile into the series as a slice, regardless of if it contains multiple volumes- 2: Forcing the series of slices to respect the order passed in the registration payload
You can do so by adding an optional argument to the base of the payload as follows:
payload = { "items": [ ... ], "dataset_slug": dataset_slug, "storage_slug": storage_name, "options": {"ignore_dicom_layout": True} }
Multi-Planar View
To register medical volumes and extract the axial, sagittal, and coronal views:
- 1: Include the
"extract_views": "true"payload field - 2: The specified
slot_namemust be0
payload = {
"items": [
{
"path": "/",
"slots": [
{
"type": "dicom",
"slot_name": "0",
"storage_key": "001/slice1.dcm",
"file_name": "slice1.dcm",
"extract_views": "true"
}
],
"name": "001.dcm"
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}Registration Through darwin-py
If you're using read-write registration, you can simplify item registration using the darwin-py SDK. Below is an example Python script demonstrating how to register single-slotted items with darwin-py:
from darwin.client import Client
# Define your storage keys
storage_keys = [
"path/to/first/image.png",
"path/to/second/image.png",
"path/to/third/image.png",
]
# Populate your Darwin API key, team slug, target dataset slug, and storage configuration name in Darwin
API_KEY = "YOUR_API_KEY_HERE"
team_slug = "team_slug"
dataset_slug = "dataset_slug"
storage_config_name = "your_bucket_name"
# Retreive the dataset and connect to your bucket
client = Client.from_api_key(API_KEY)
dataset = client.get_remote_dataset(dataset_identifier=f"{team_slug}/{dataset_slug}")
my_storage_config = client.get_external_storage(name=storage_config_name, team_slug=team_slug)
# Register each storage key as a dataset item
results = dataset.register(my_storage_config, storage_keys)
# Optionally inspect the results of each item
print(results)Note: The first step is to define your storage keys. These can be read in from a file, or returned from the SDK of your cloud provider (see below), but they must be structured as a list of strings.
By default, darwin-py will register every item in the root directory of the chosen dataset. You can recreate the folder structure defined by your storage keys in the Darwin dataset using the preserve_folders option:
results = dataset.register(my_storage_config, storage_keys, preserve_folders=True)If you're registering videos, you can specify the FPS that frames should be sampled from each video at with the optional fps argument:
fps = 10
results = dataset.register(my_storage_config, storage_keys, fps=fps)If you're registering DICOM volumes and wish to use multi-planar view, you can use the optional multi_planar_view argument:
results = dataset.register(my_storage_config, storage_keys, multi_planar_view=True)If you want to register multi-slotted items, you can use the multi_slotted argument. Note that in this case your storage keys will need to be formatted as a dictionary of lists, where:
- Each dictionary key is an item name
- Each dictionary value is a list of storage keys for the item
storage_keys = {
"item1": ["path/to/first/image.png", "path/to/second/image.png"],
"item2": ["path/to/third/image.png", "path/to/fourth/image.png"],
"item3": ["my/sample/image.png", "my/sample/video.mp4", "my/sample/pdf.pdf"]
}
results = dataset.register(my_storage_config, storage_keys, multi_slotted=True)
Slot names & folder structuresIf using darwin-py to register multi-slotted items, please note that:
- Each slot will be given a name equivalent to the filename in the storage key
- If using
preserve_folders=True, the item will be registered in the dataset directory specified by the first storage key in each list
If you'd prefer to read your storage keys directly from your external storage, you can do so using your cloud provider's SDK. Below is an example showing how to get all storage keys from a specific AWS S3 bucket directory using AWS boto3:
import boto3
def list_keys_in_bucket(bucket_name):
all_keys = []
s3 = boto3.client("s3")
paginator = s3.get_paginator("list_objects_v2")
pages = paginator.paginate(Bucket=bucket_name, Prefix="my/bucket/directory/")
for page in pages:
for obj in page["Contents"]:
key = obj["Key"]
if not key.endswith("/"):
all_keys.append(key)
return all_keys
storage_keys = list_keys_in_bucket("s3-bucket-name")Read-Only Registration
Registering any read-only file involves sending a POST request to the below API endpoint with a payload containing instructions for Darwin on where to access the item:
f"https://darwin.v7labs.com/api/v2/teams/{team_slug}/items/register_existing_readonly"Please be aware that registering read-only items requires that:
- 1: A thumbnail file for each item is generated and available in your external storage
- 2: Video files have a set of high-quality and low-quality frames pre-extracted and available in your external storage
We recommend using mogrify for thumbnail generation:
> mogrify -resize "356x200>" -format jpg -quality 50 -write thumbnail.jpg large.png
Don't use Original Images as ThumbnailsIt is strongly recommended that you don't use the originally image as your thumbnail. This can lead to CORS issues in some browsers, preventing access to the item.
The Basics
Below is a Python script covering the simplest case of registering a single image file as a dataset item in a dataset. A breakdown of the function of every field within is available below the script.
import requests
# Define constants
api_key = "your_api_key_here"
team_slug = "your-team-slug-here"
dataset_slug = "your-dataset-slug-here"
storage_name = "your-storage-bucket-name-here"
# Populate request headers
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"ApiKey {api_key}"
}
# Define registration payload
payload = {
"items": [
{
"path": "/",
"type": "image",
"storage_key": "car_folder/car_1.png",
"storage_thumbnail_key": "thumbnails/car_1_thumbnail.png",
"height": 1080,
"width": 1920,
"name": "car_1.png",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}
# Send the request
response = requests.post(
f"https://darwin.v7labs.com/api/v2/teams/{team_slug}/items/register_existing_readonly",
headers=headers,
json=payload
)
# Inspect the response for errors
body = response.json()
if response.status_code != 200:
print("request failed", response.text)
elif 'blocked_items' in body and len(body['blocked_items']) > 0:
print("failed to register items:")
for item in body['blocked_items']:
print("\t - ", item)
if len(body['items']) > 0: print("successfully registered items:")
for item in body['items']:
print("\t - ", item)
else:
print("success")-
api_key: Your API key -
team_slug: Your sluggified team name -
dataset_slug: The sluggified name of the dataset to register the file in -
storage_name: The name of your storage integration in your configuration. For example:
Payload-specific fields & concepts:
items: It's possible to register multiple items in the same request, thereforeitemsis a list of dictionaries where each dictionary corresponds to one dataset itempath: The folder path within the Darwin dataset that this item should be registered attype: The type of file being registered. It can beimage,video, orpdf. This instructs us on how to treat the file so it can be viewed correctlystorage_keyandstorage_thumbnail_key: The exact file paths to the file and it's corresponding thumbnail in your external storage. This file path is case sensitive, cannot start with a forward slash, and is entered slightly differently depending on your cloud provider:- For AWS S3, exclude the bucket name. For example if the full path to your file is
s3://example-bucket/darwin/sub_folder/example_image.jpgthen yourstorage_keymust bedarwin/sub_folder/example_image.jpg - For Azure blobs, include the container name. For example if the full path to your file is
https://myaccount.blob.core.windows.net/mycontainer/myblob.jpgthen yourstorage_keymust bemycontainer/darwin/sub_folder/myblob.jpg - For GCP Buckets, exclude the bucket name. For example if the full path to your file is
gs://example-bucket/darwin/sub_folder/example_image.jpg, then yourstorage_keymust bedarwin/sub_folder/example_image.jpg
- For AWS S3, exclude the bucket name. For example if the full path to your file is
heightandwidth: The exact height and width of the main image. If these are included incorrectly, then uploaded annotations will appear in the incorrect part of the screen or incorrectly scaledname: The name of the resulting dataset item as it appears in Darwin. This can be any name you choose, but we strongly recommend giving files the same or similar names to the externally stored files
Registering files in Multiple Slots
If you need to display multiple files next to each other simultaneously, you'll need to register them in different slots. Please refer to this article to gain an understanding of the concept of slots.
To register a dataset with multiple slots from external storage, the registration payload changes in structure as follows:
payload = {
"items": [
{
"path": "/",
"slots": [
{
"slot_name": "0",
"type": "image",
"storage_key": "car_folder/car_1.png",
"storage_thumbnail_key": "thumbnails/car_1_thumbnail.png",
"height": 1080,
"width": 1920,
"file_name": "car_1.png",
},
{
"slot_name": "1",
"type": "image",
"storage_key": "car_folder/car_2.png",
"storage_thumbnail_key": "thumbnails/car_2_thumbnail.png",
"height": 1080,
"width": 1920,
"file_name": "car_2.png",
},
{
"slot_name": "2",
"type": "video",
"storage_key": "video_folder/car_video.mp4",
"storage_thumbnail_key": "thumbnails/car_video_thumbnail.png",
"file_name": "cars.mp4",
"sections": [
{
"section_index": 1,
"height": 1080,
"width": 1920,
"storage_hq_key": "video_folder/car_video/frame_1_hq.png",
"storage_lq_key": "video_folder/car_video/frame_1_lq.png",
},
{
"section_index": 2,
"height": 1080,
"width": 1920,
"storage_hq_key": "video_folder/car_video/frame_2_hq.png",
"storage_lq_key": "video_folder/car_video/frame_2_lq.png",
},
],
},
],
"name": "cars",
}
],
"dataset_slug": dataset_slug,
"storage_slug": storage_name,
}Important points are:
- Because the dataset item now contains multiple files, we need to break the item up into separate slots each with a different
slot_name. Slots can be named any string, so long as they are unique for items that need to go into separate slots - Each item in
slotsis given a newfile_namefield. This is distinct from thenamefield which will be the name of the resulting dataset item in Darwin.file_nameshould match the exact file name of the file in that slot (i.e. it should match the last part ofstorage_key) - No two files can be registered to the same slot
- It's possible to register different filetypes in different slots within the same dataset item. For example, above we have 2 slots containing images and a third containing a video
Registering DICOM Files
Unlike when using read-write storage, DICOM (.dcm) files cannot be registered directly in read-only. Instead, DICOM slices and series must first be converted to images and stored in your external bucket. Individual slices can then be registered as image items, and series of slices can be registered as video items.
Registering Videos with darwin-py
The darwin-py SDK offers helper methods to process videos locally, upload the necessary artifacts (frames, thumbnails, and the video itself) to your storage, and register them in Darwin.
This is the recommended method for registering videos with both Read-Only and Read-Write storage configurations. By performing artifact extraction locally, you significantly reduce both the time required and the amount of data transferred between our infrastructure and your storage.
Write Access RequiredThe machine running this SDK script requires Write Access to your storage bucket/container to upload the processed artifacts and video files, regardless of whether your Darwin storage configuration is Read-Only or Read-Write.
Prerequisites
- darwin-py: Version 3.4.0 or higher.
- FFmpeg: You must have FFmpeg version 5 or higher installed on the machine running the script.
Supported Providers
The SDK supports uploading artifacts to:
- AWS S3
- Google Cloud Storage (GCP)
- Azure Blob Storage
Authentication Setup
The SDK uses your local environment configuration to authenticate with your storage provider. Ensure you have the appropriate variables set before running your script.
AWS S3
Ensure your ~/.aws/credentials file is configured, or set the following environment variables:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_REGION
Google Cloud Storage (GCP)
Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to the absolute path of your service account JSON key file.
Azure Blob Storage
Set the AZURE_STORAGE_CONNECTION_STRING environment variable.
Alternatively, if you are running in an Azure environment with Managed Identity configured, the SDK will automatically use DefaultAzureCredential.
Using register_locally_processed
register_locally_processedThe register_locally_processed method is the unified interface for registering locally processed videos. It supports both single-slotted and multi-slotted items through a simple parameter toggle.
Single-Slotted Videos
Use register_locally_processed with a list of video file paths to register each video as a separate item in the dataset.
from darwin.client import Client
# 1. Initialize Client
client = Client.from_api_key("YOUR_API_KEY")
dataset = client.get_remote_dataset("team-slug/dataset-slug")
# 2. Get Storage Configuration
# This must match a configured storage integration in your V7 team
# Works with both Read-Only and Read-Write configurations
storage = client.get_external_storage(team_slug="your-team-slug", name="your-storage-config-name")
# 3. Define Local Video Paths
# These files must exist on your local machine
video_files = [
"/path/to/local/video1.mp4",
"/path/to/local/video2.mp4"
]
# 4. Process & Register
# This will:
# - Extract frames and thumbnails locally
# - Upload the video and artifacts to your storage
# - Register the items in Darwin
results = dataset.register_locally_processed(
object_store=storage,
files=video_files,
fps=0.0, # 0.0 = use native video FPS
path="/videos", # Optional: Folder path within the dataset
)
print(results)Multi-Slotted Videos
Use register_locally_processed with multi_slotted=True to register items containing multiple video slots (e.g., synchronized multi-view recordings).
# ... (Client setup as above) ...
# Define items and their corresponding video files
# Dictionary Keys = Item Names
# Dictionary Values = List of local video files for that item
video_mapping = {
"scene_001": [
"/path/to/scene_001/camera_front.mp4",
"/path/to/scene_001/camera_back.mp4"
],
"scene_002": [
"/path/to/scene_002/camera_front.mp4",
"/path/to/scene_002/camera_back.mp4"
]
}
# Process & Register
# Slot names will be derived from the filenames (e.g., 'camera_front.mp4')
results = dataset.register_locally_processed(
object_store=storage,
files=video_mapping,
path="/multi-view",
multi_slotted=True
)
print(results)Reducing Artifact Size
The extract_preview_frames and primary_frames_quality parameters allow you to reduce the size of extracted artifacts at the expense of quality. This can be useful when storage costs or upload bandwidth are a concern.
extract_preview_frames
extract_preview_frames- Default:
True - When
True: Extracts separate low-quality preview frames used for playback scrubbing in the Darwin UI. - When
False: Skips preview frame extraction. The system will use video segments for previews instead, which results in less precise, lower-quality previews during playback scrubbing.
primary_frames_quality
primary_frames_quality- Default:
1(PNG format - lossless) - Range:
1to311= PNG format (lossless, highest quality, largest file size)2= JPEG with best quality31= JPEG with lowest quality (smallest file size)
Lower values produce higher quality frames but larger files. Using JPEG (values 2-31) instead of PNG can significantly reduce storage requirements, especially for high-resolution videos.
How It Works
When you run register_locally_processed, the SDK performs the following steps for each video:
-
Extraction: Uses
ffmpeg(via the SDK's extractor) to extract the required artifacts locally:- A thumbnail image.
- A manifest file.
- Video segments.
- Frame images.
- Preview frames (if
extract_preview_frames=True).
-
Upload: Uploads the original video file and all extracted artifacts to your external storage location. The path structure in your bucket will generally follow:
prefix/uuid/files/uuid/. -
Registration: Sends the registration payload to Darwin, pointing to the uploaded artifacts.
-
Cleanup: Removes extracted artifacts from the local file system.
Updated 7 months ago