Voxel51 Integration
The V7 integration with Voxel51 allows you to annotate curated subsets of your data, increasing efficiency with reduced data volumes. Users can easily annotate data & transfer it seemlessly between the platforms.
Key Benefits of the Integration
Dataset curation for smarter annotation
FiftyOne by Voxel51 is the leading open-source toolkit for building high-quality datasets and computer vision models. It helps to visualise, curate, manage, and QA data. Additionally, it helps to automate the workflows that support enterprise machine learning. FiftyOne helps users identify the most relevant samples from datasets to send to V7 for annotation. It does this by providing a variety of tools and workflows to:
- Explore and balance your datasets by class and metadata distribution
- Visualize, de-duplicate, sample, and pre-label your data distributions using embeddings
- Perform automated pre-labeling with off-the-shelf or custom models
These workflows enable the creation of diverse, representative data subsets while minimizing data volume, getting you the most out of your annotation budget and boosting model performance.
Dataset improvements for model fine-tuning and evaluation
This integration allows for efficient optimization and augmentation of existing datasets to boost model performance.
FiftyOne enables powerful image and object-level annotation review and QA workflows. The platform’s embedding visualization, compatible with off-the-shelf and custom models, can be used to help analyze the quality of the annotations and the dataset to identify mistakes and areas for improvement.
By adding model predictions to a dataset for comparison with ground truth, or using the built-in similarity search features and vector database integrations, you can identify the difficult samples with targeted precision and pinpoint inaccurate annotations. FiftyOne’s sample and label-level tags, as well as saved views, make it easy to mark samples for re-annotation back in V7.
Seamless data transfers and support for all data formats
Data can be easily sent back and forth between Voxel51 and V7 via an API to reduce the time and effort needed for transfers and ensure data security. The integration allows for seamless conversion of all data formats, retaining all existing annotations (including labels made in other tools).
V7 supports many formats of data: Images, videos, and medical imagery. Powered with auto-annotation, specialized video labelling, and SAM integration, labelling teams can annotate data faster without sacrificing quality.
Notably, V7 supports DICOM, NIfTI, and WSI imagery, showcasing its commitment to delivering fit-for-purpose infrastructure for industries of all types.
Using V7 and Voxel51 together
Voxel51 ConceptsThe following guide relies on basic knowledge of several Voxel51 concepts. To familiarise yourself with the relevant concepts, please refer to Voxel51's documentation, particularly on:
The integration between Voxel51’s FiftyOne and V7 Darwin is provided by darwin_fiftyone.
It enables FiftyOne users to send subsets of their datasets to Darwin for annotation and review. The annotated data can then be imported back into FiftyOne.
Integration Setup
To start, you need to install the fiftyone and darwin-fiftyone Python packages:
pip install fiftyone && pip install darwin-fiftyoneNext, we need to configure authentication.darwin-fiftyone authenticates with V7 Darwin by referring to the API key in the following configuration file. Therefore, create this file and populate it with your Darwin API key
cat ~/.fiftyone/annotation_config.json
{
"backends": {
"darwin": {
"config_cls": "darwin_fiftyone.DarwinBackendConfig",
"api_key": "d8mLUXQ.**********************"
}
}
}Loading example data in FiftyOne
Let’s start by loading example data into FiftyOne.
import fiftyone.zoo as foz
import fiftyone as fo
# Load an open dataset from Voxel51
dataset = foz.load_zoo_dataset("quickstart", dataset_name="quickstart-example")
# Launch the Voxel51 application
session = fo.launch_app(dataset)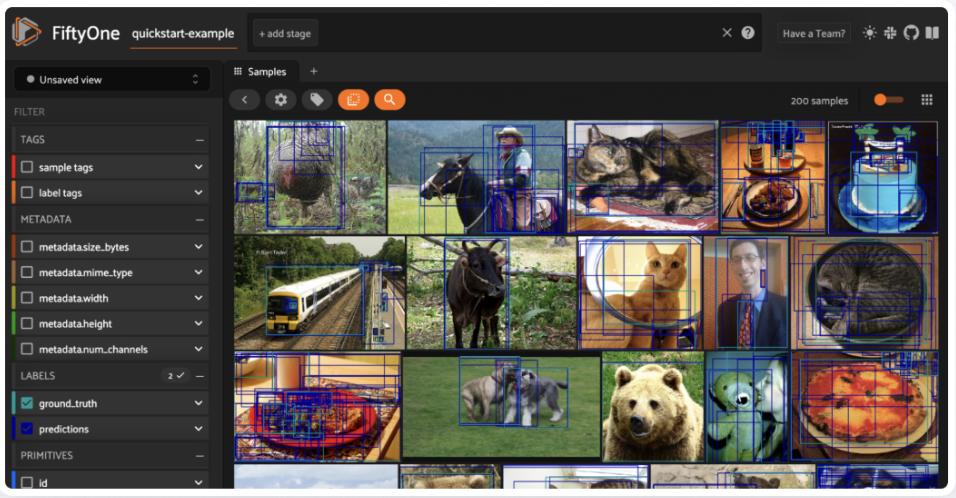
Annotation
Next, let’s load this data into V7 for annotation and refinement. To illustrate, let's upload all samples from this open dataset as dataset items into a Darwin dataset named quickstart-example.
If the dataset doesn't already exist in Darwin, it will be created.
Defining a Label Schema
Before you send a dataset or a dataset view for annotation, you should define a label schema outlining the classes and properties you want to annotate in this annotation run. The integration will automatically create and add the classes and properties specified so you don't need to do this in the Darwin UI.
Below is a simple example which will result in a single bounding box class named Car in the Darwin dataset. The class will be created with a single select property called attr1 with the values val1 and val2.
label_schema = {
"ground_truth": {
"type": "detections",
"classes": ["Car"],
"attributes": {
"attr1": {
"type": "select",
"values": ["val1", "val2"],
},
}
}All classes created through darwin-fiftyone will have the text sub-annotation type enabled
As of darwin-fiftyone version 1.1.17, you can create classes with the instance ID sub-annotation type enabled by associating an attribute with no values of type instance_id with the class. For example, the below label schema will create a bounding box class Car with the instance ID sub-type enabled.
label_schema = {
"ground_truth": {
"type": "detections",
"classes": ["Car"],
"attributes": {
"attr1": {
"type": "select",
"values": ["val1", "val2"],
},
"my_ids": {"type": "instance_id"},
},
}
}
When importing annotations from Voxel51 to Darwin, for all classes with the instance ID sub-type enabled, any present label indices from Voxel51's schema will be assigned as instance IDs in Darwin.
For more information, please see the Voxel51 documentation on how to create a label schema.
Next, we use the annotate() method to send data and any annotations for the classes defined in the label_schema to a Darwin dataset:
# Create a unique identifier for this annotation run
anno_key = "unique_identifier"
dataset.annotate(
anno_key,
label_schema = label_schema,
launch_editor=True,
backend="darwin",
dataset_slug="quickstart-example",
)anno_key is a unique alphanumeric string for an annotation run in the V7 platform. It should start with a letter. It is not related to the V7 API Key used
Annotating Videos
The integration also supports video annotation. You should call the ensure_frames method on your dataset or dataset view before annotation so that unannotated videos have frame ids
dataset.ensure_frames()
dataset.annotate(
anno_key,
label_schema = label_schema,
launch_editor=True,
backend="darwin",
dataset_slug="quickstart-example-video",
)Annotating multi-slotted data
As of v.1.1.9 of the darwin-fiftyone integration, you can connect a 51 grouped dataset into a multi-slotted view in V7 allowing you to annotate related items in the same image canvas.
- Firstly you need to make sure that your dataset is a 51 grouped dataset. See instructions here
- Then prepare your dataset for annotation. it is critical to use the
select_group_slices()method on your dataset or dataset view before annotation as theannotatemethod doesn't directly support grouped collections
Here is an example using the quickstart-groups dataset
import fiftyone as fo
import fiftyone.zoo as foz
group_dataset = foz.load_zoo_dataset("quickstart-groups")
group_ids = group_dataset.take(3).values("group.id")
group_view = group_dataset.select_groups(group_ids)
groups = group_view.select_group_slices(media_type="image")Set the Groups argument to True otherwise each sample will be added as a single slotted item in V7
groups.annotate(
anno_key,
label_schema = label_schema,
launch_editor=True,
backend="darwin",
dataset_slug="group-test-dataset",
Groups=True,
)Annotating files from external storage
If you’re a FiftyOne Teams customer and work with externally stored or cloud-backed files, you will be able to load items directly from your cloud storage by following the three additional steps:
- 1: Set up V7 external storage settings with your cloud provider
- 2: Configure the file paths of your dataset samples to the full file paths of your externally stored data. For example:
- AWS S3:
s3://{bucket_name}/directory/file.jpg - Azure Blob:
https://{storage_account}.blob.core.windows.net/{container_name}/directory/file.jpg - GCP Bucket:
gs://{bucket_name}/directory/file.jpg
- AWS S3:
- 3 Populate the optional
external_storageargument in calls of theannotate()method with the name of your storage configuration, for example:
dataset.annotate(
anno_key,
label_schema = label_schema,
launch_editor=True,
backend="darwin",
dataset_slug="my_dataset,
external_storage="my_storage_name"
)Sending Data Back to Voxel51
After the annotations and reviews are completed in Darwin, you can fetch the updated data as follows:
dataset.load_annotations(anno_key)Checking Annotation Job Status
To check the progress of your annotation job, you can call the check_statusmethod:
dataset.load_annotations(anno_key)
results = dataset.load_annotation_results(anno_key)
results.check_status()Cleanup
To delete the associated V7 dataset and workflow you can use the cleanupmethod. It should be used only when you are finished with that data in V7.
dataset.load_annotations(anno_key)
results = dataset.load_annotation_results(anno_key)
results.cleanup()
Cleanup Method UsageThe cleanup method will permanently delete the V7 workflow and dataset attached to an annotation run. Please use this very careful and ensure all data has been sent back to Voxel51 before using it.
Logging
Versions 1.1.21 and onward will generate a log file in the ~./fiftyone/v7/ directory every time the integration is used. If you run into issues using the darwin-fiftyone integration, this file can be included in reports to our support team at [email protected] to assist with troubleshooting.
You can configure the logging directory or disable the generation of a log file by setting the following environment variables:
DARWIN_FIFTYONE_LOGGING_DIRECTORY- If set, log files will be written to the configured directoryDISABLE_DARWIN_FIFTYONE_LOGGING- If set totrue, no log file will be generated when using thedarwin-fiftyoneintegration
Supported Annotation types
The darwin-fiftyone integration supports the following annotation types. These are automatically converted when transferring data from Voxel51 to V7 and vice versa:
| Voxel51 Label Type | V7 Annotation Type |
|---|---|
| Classifications | Tags |
| Detections | Bounding boxes |
| Keypoints | Keypoints |
| Polylines | Polygons or polylines (see below) |
Voxel51 represents polygons & polylines as the same datatype using the Polyline class. APolyline is a V7 polygon is it's closed attribute is True. For example:
import fiftyone as fo
sample = fo.Sample(filepath="/path/to/image.png")
# A simple polyline
polyline1 = fo.Polyline(
points=[[(0.3, 0.3), (0.7, 0.3), (0.7, 0.3)]],
closed=False,
filled=False,
)
# A closed, filled polygon with a label
polyline2 = fo.Polyline(
label="triangle", # `label` is analagous to V7 annotation classes / names
points=[[(0.1, 0.1), (0.3, 0.1), (0.3, 0.3)]],
closed=True,
filled=True,
)
Annotating Complex PolygonsThe integration also supports annotating complex polygons. These are polygons with more than 1 path of points. Because Voxel51 doesn't natively support complex polygons, you'll need to pass them as
filled=False. In these cases, the format returned to Voxel51 will be unfilled closed polylines
Model training and next steps
The data annotated in V7 can now be further reviewed and refined before it’s used for model training.
FiftyOne has a variety of tools to enable easy integration with your model training pipelines. You can easily export your data in common formats like COCO or YOLO suitable for use with most training packages. FiftyOne also provides workflows for popular model training libraries such as PyTorch, PyTorch Lightning Flash, and Tensorflow.
With FiftyOne’s plugins architecture, custom training workflows can be directly integrated into the FiftyOne App and become available at the click of a button. The delegated execution feature lets you process the workflows on dedicated compute nodes.
Once a model is trained, you can easily run inference, load the model predictions back into FiftyOne, and evaluate them against the ground truth annotation.
# Load an existing dataset with predictions
dataset = foz.load_zoo_dataset("quickstart")
# Evaluate model predictions
dataset.evaluate_detections(
"predictions",
gt_field="ground_truth",
eval_key="eval",
)FiftyOne’s evaluation and filtering capabilities make it easy to spot discrepancies between model predictions and ground truth, including annotation errors or difficult samples where your model underperforms.
Tag annotation mistakes in FiftyOne for re-annotation in V7, and add the difficult samples to the next iteration of your training set. Take a snapshot of your dataset and move on to the next round of improvements.
Dataset Versioning
FiftyOne Teams also includes dataset versioning, which means every annotation and model you ran can now be captured and versioned in a history of dataset snapshots. Dataset snapshots in FiftyOne Teams can be created, browsed, linked to, and re-materialized with ease—without complex naming conventions or manual tracking of versions
Updated 10 months ago