Use the Python Library to manage your data
An SDK how-to guide. SDK power-users can refer to our full SDK docs generated from our source code here
Getting started
Before we can put the Python Library to use, we'll want to make sure that we have three bases covered:
1. Install Python 3.10 or above
To use the most up-to-date version of Darwin's Python Library, we'll want to make sure that we have Python 3.10 or above installed. You can find all supported Python versions here.
If you don't already have Python installed, you can download the most recent version here.
2. Install the Darwin Software Development Kit
To install the Darwin SDK, open the Command Prompt in Windows, or Terminal on a Mac, and enter the following command:
pip install darwin-pyIf you've previously installed the SDK, make sure you're using the most up-to-date version by entering the following instead:
pip install darwin-py --upgrade3. Generate an API key
You can generate an API key within V7 by selecting the gear icon and heading to API Keys. When generating the key, we're looking to accomplish two things:
- Encoding the team whose data we will be managing
- Encoding the permissions for the tasks that we want to run.
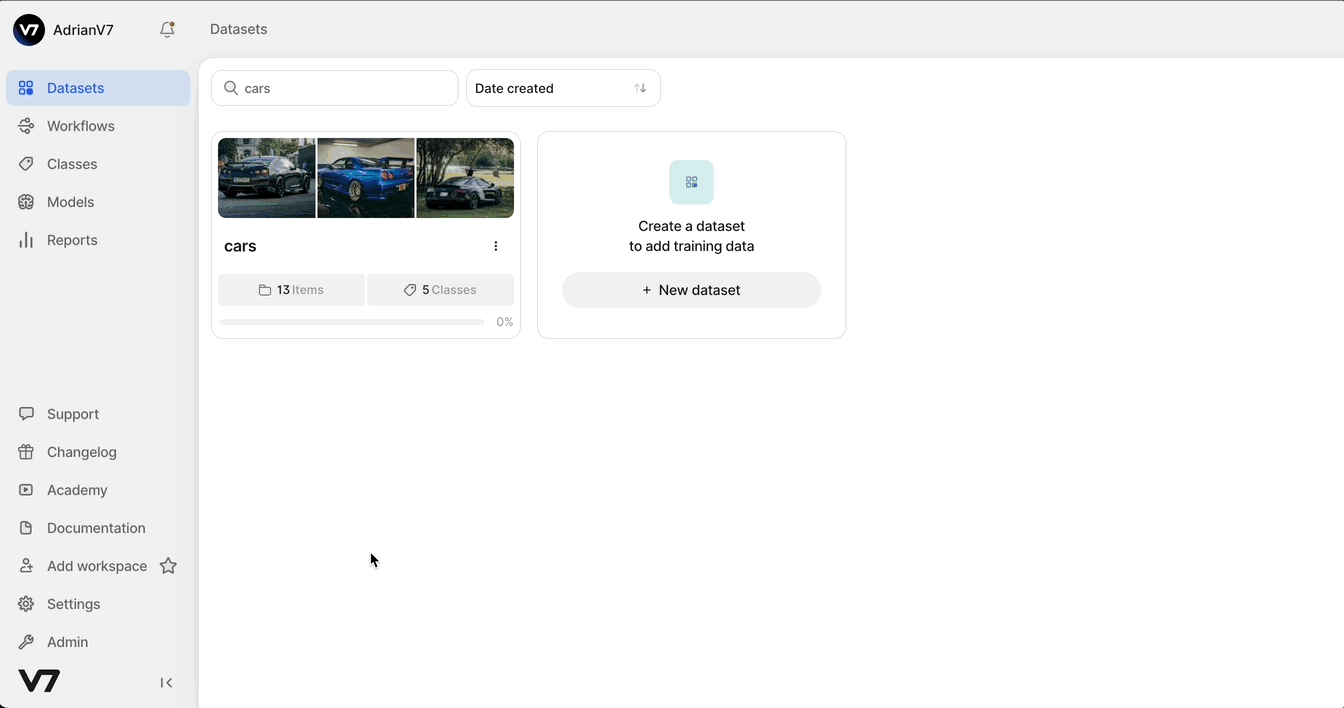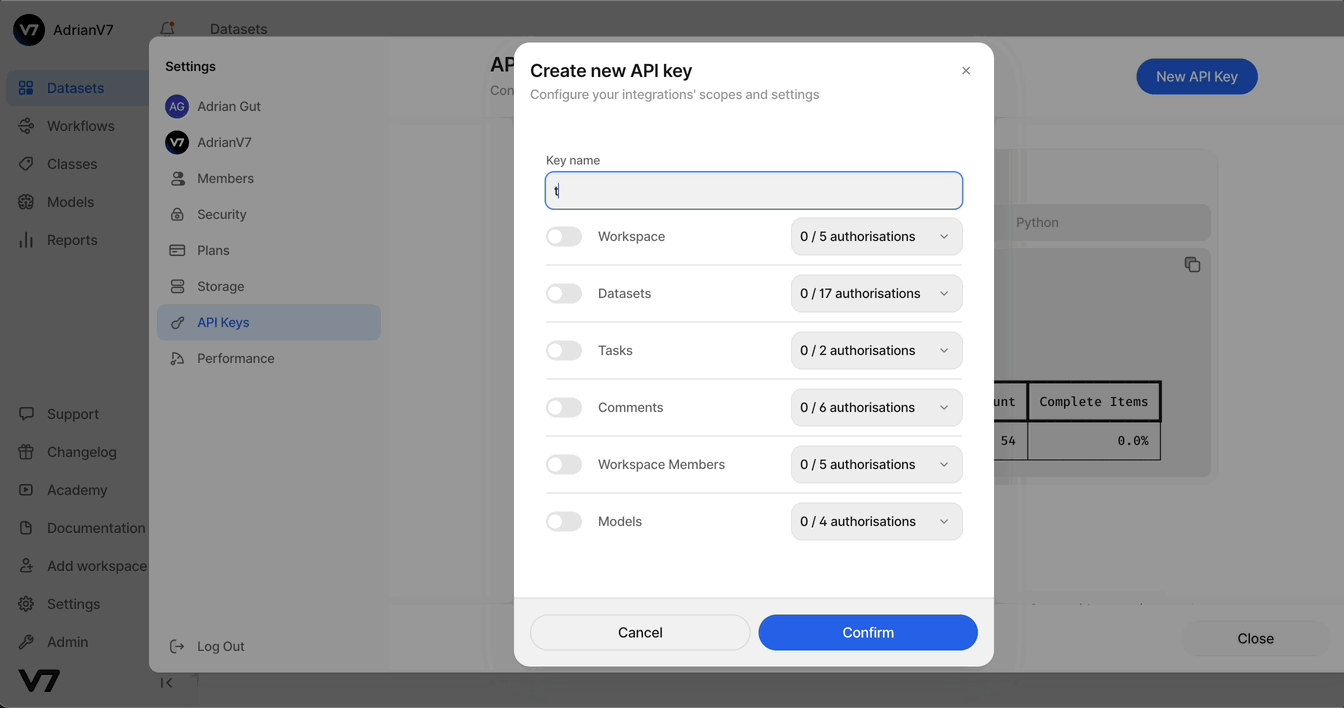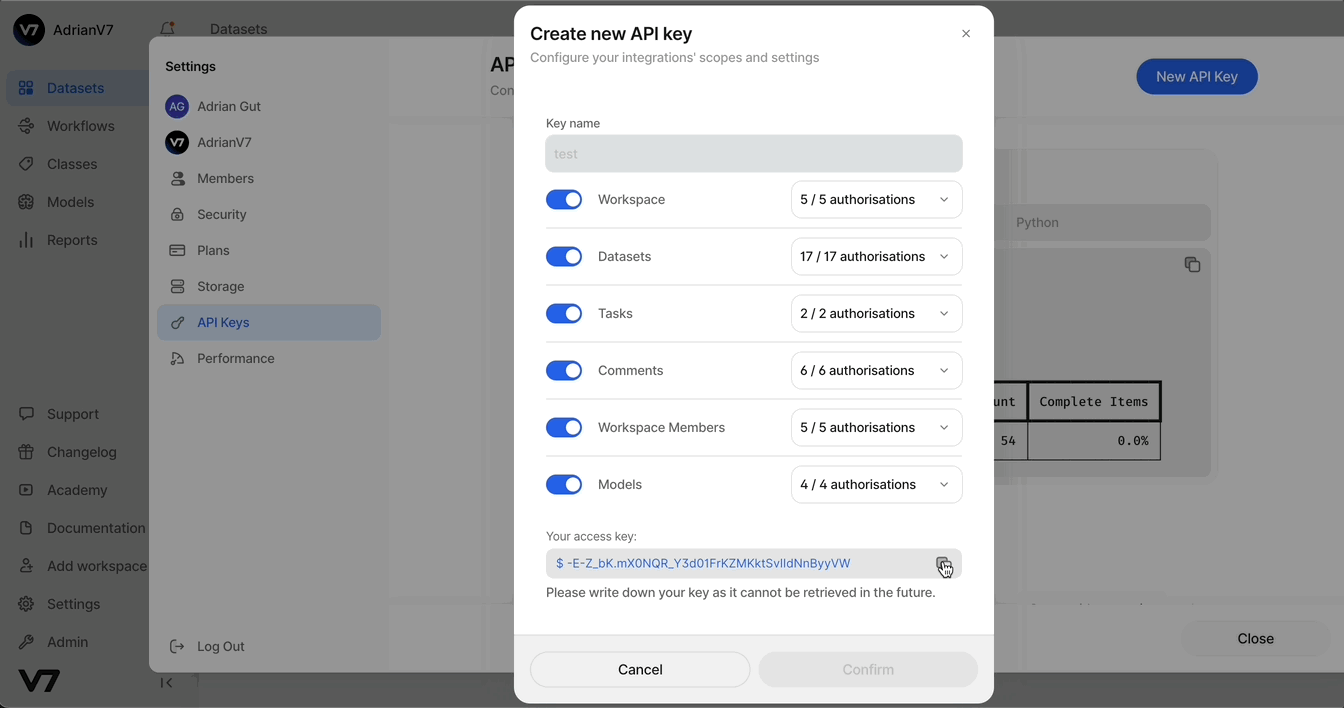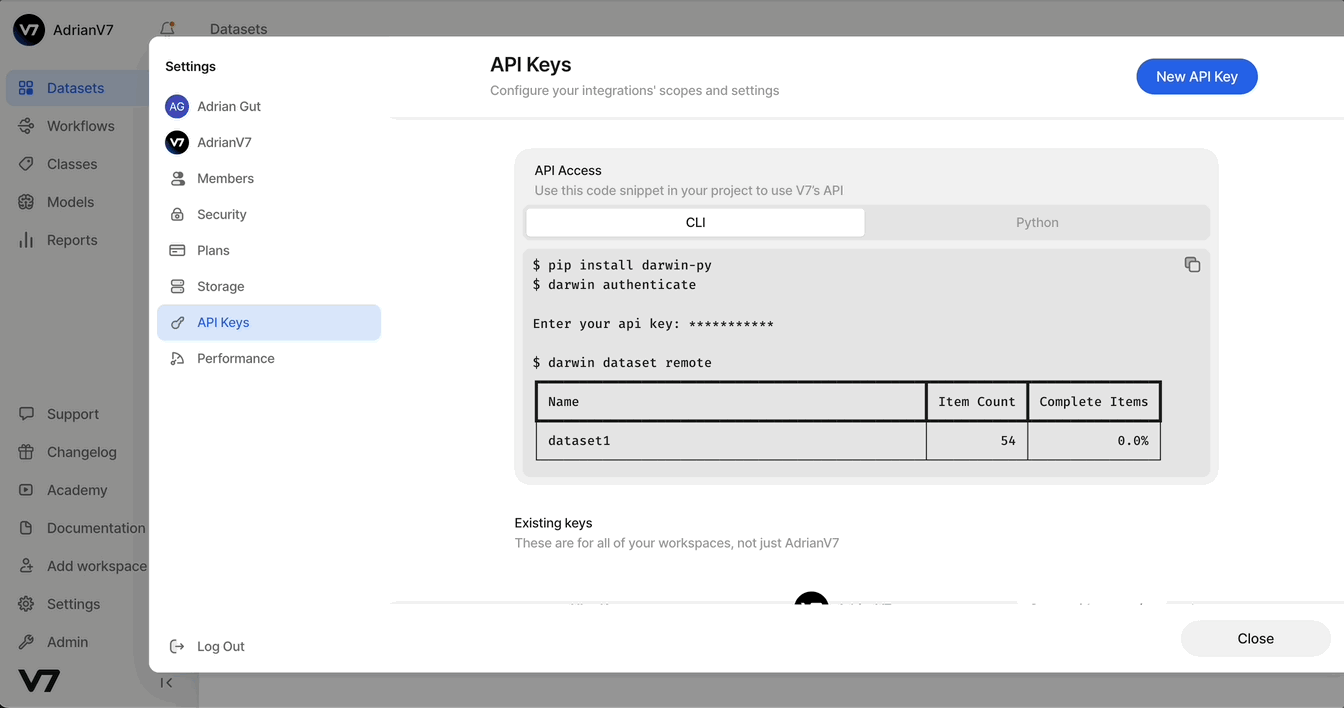
Hold on to your API key! We'll need it for our next task - creating a dataset.
Team and Dataset SlugsYou will often be asked to enter a
team-slugordataset-slugas a parameter. If you are unsure on how to generate this then you can use the Slugify Python library.
Updated 3 months ago