Import files with CLI commands
A CLI how-to guide. SDK power-users can refer to our full SDK docs generated from our source code here
Some datasets may contain too much data for a simple drag and drop. You may also want to import existing annotations to the images you've imported. In each case, CLI commands will provide the most effective way to get the data you want into V7.
You will need Python 3.10 or higher installed to complete these steps
Basics for using CLI Commands
Open the Command Prompt in Windows, or Terminal on a Mac.
For each command in these instructions, paste the text into the Command Prompt or Terminal and hit Enter to run the command.
1. Setup
Install or update the Darwin Software Development Kit using these instructions.
2. Authentication
Next, to enable remote operations, you'll need to generate a team-specific API key.
In V7, head to the Settings menu and click API Keys to generate a new key
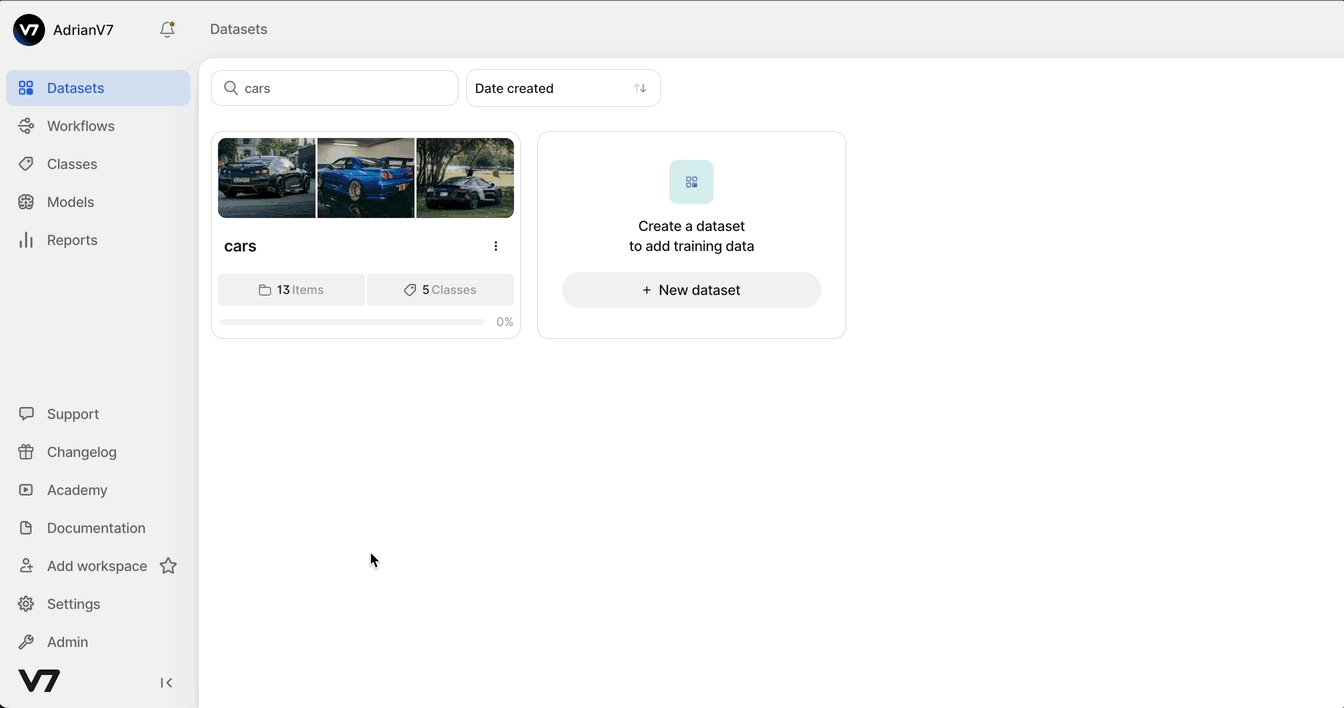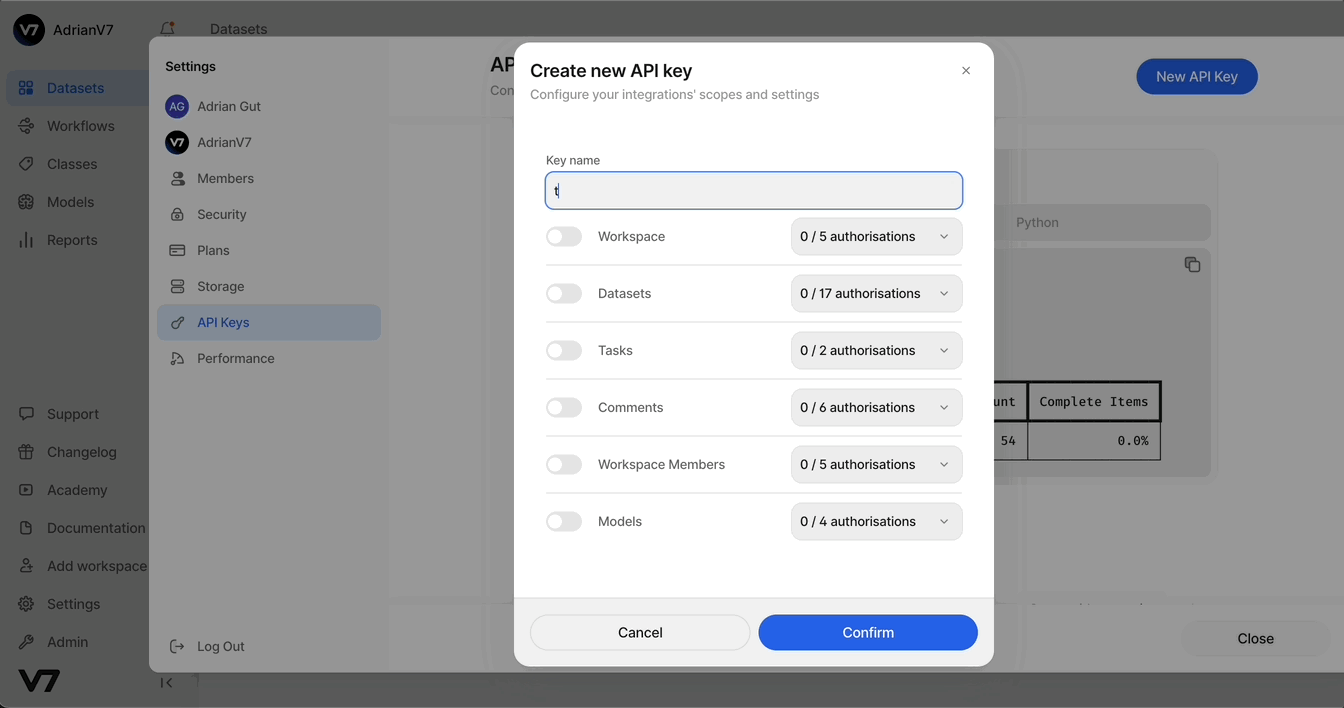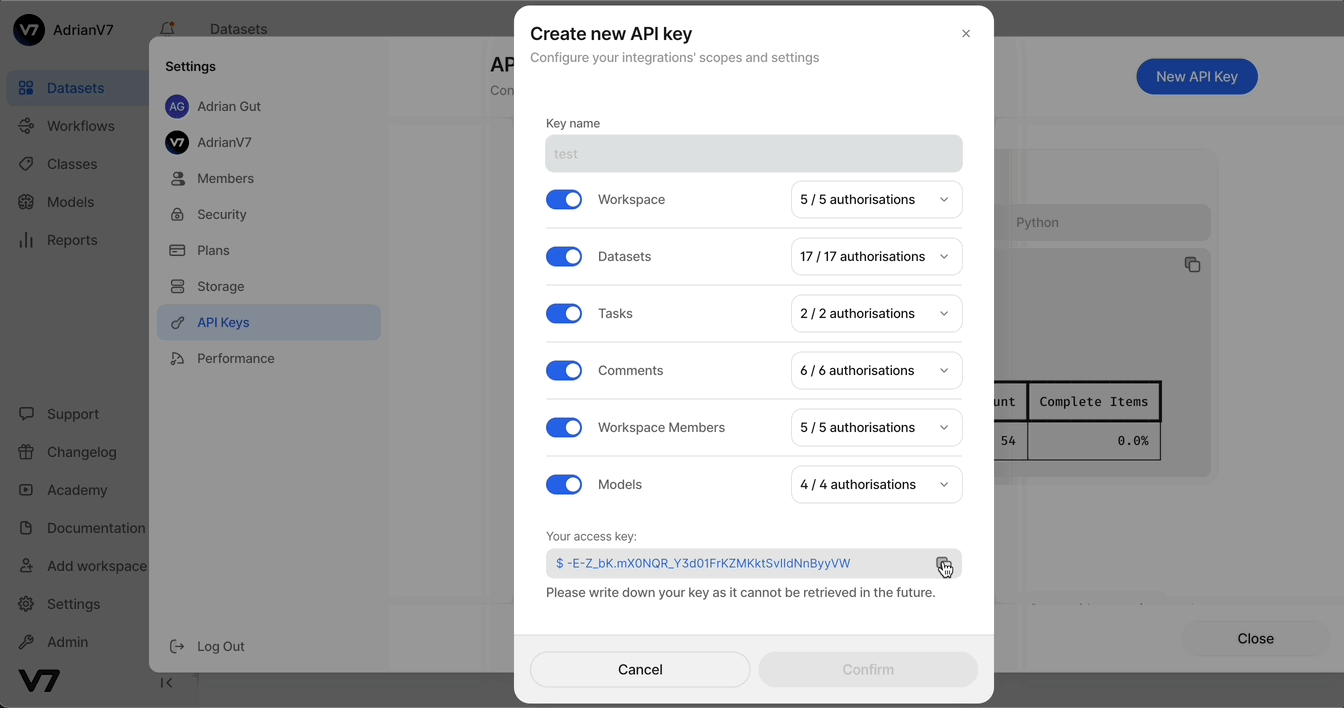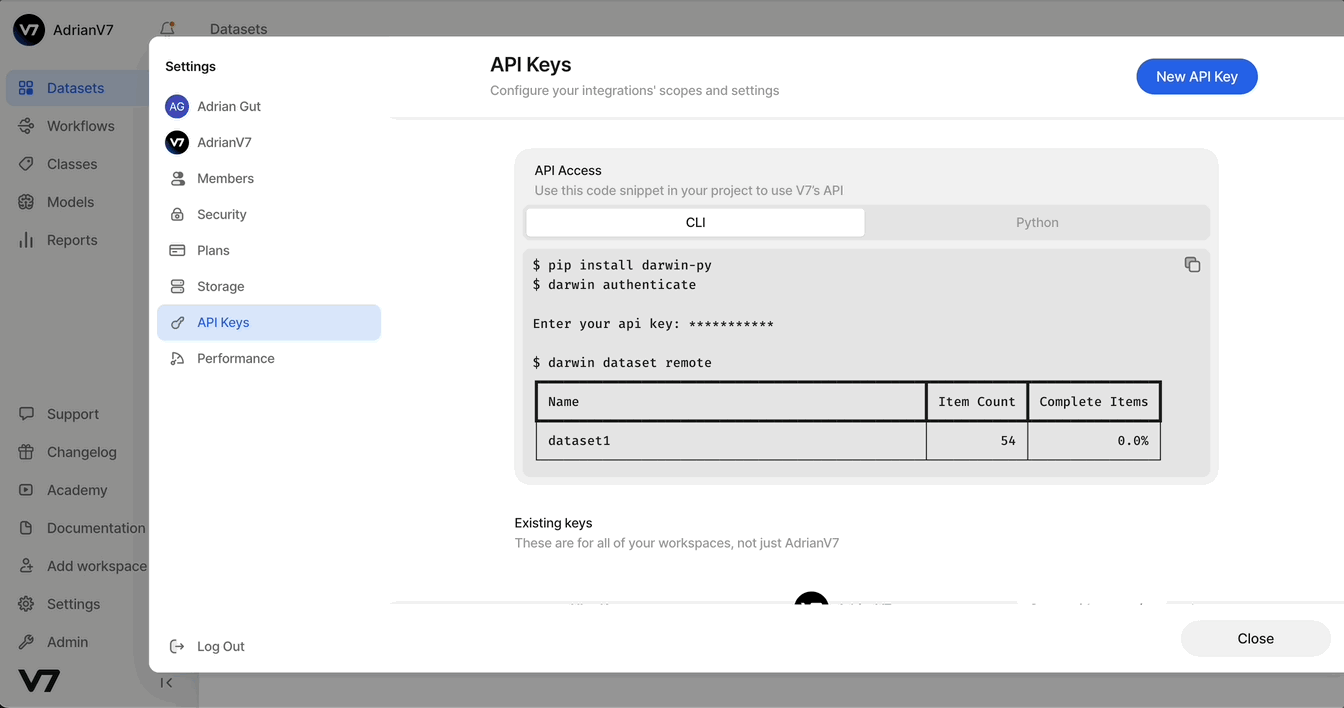
Name the key, select all access permissions, and click Create. Then, copy the access key to your clipboard—you’ll need it shortly
Back in the Command Prompt/Terminal, enter the command below:
darwin authenticateYou'll then be prompted to enter the API key you just created. Since the key is encrypted, it won’t be visible when you paste it into the Command Prompt or Terminal—this is normal. Go ahead and hit Enter after pasting the API key.
Enter Y and hit Enter when prompted to make ****your team in V7 the default team.
This will create a configuration file on your device at ~/.darwin/config.yaml.
Now you're ready to upload your data.
3. Upload data
Uploading data uses the 'push' command, which is detailed on this page, but generally follows this structure:
darwin dataset push team-slug/dataset-slug /path/to/files/Alternatively, you can fetch a pre-written command directly from V7, as shown in the image below. Select New Dataset or Add Data in an existing dataset to copy the Command Line Upload command. This command allows you to upload data from your device to a V7 dataset.
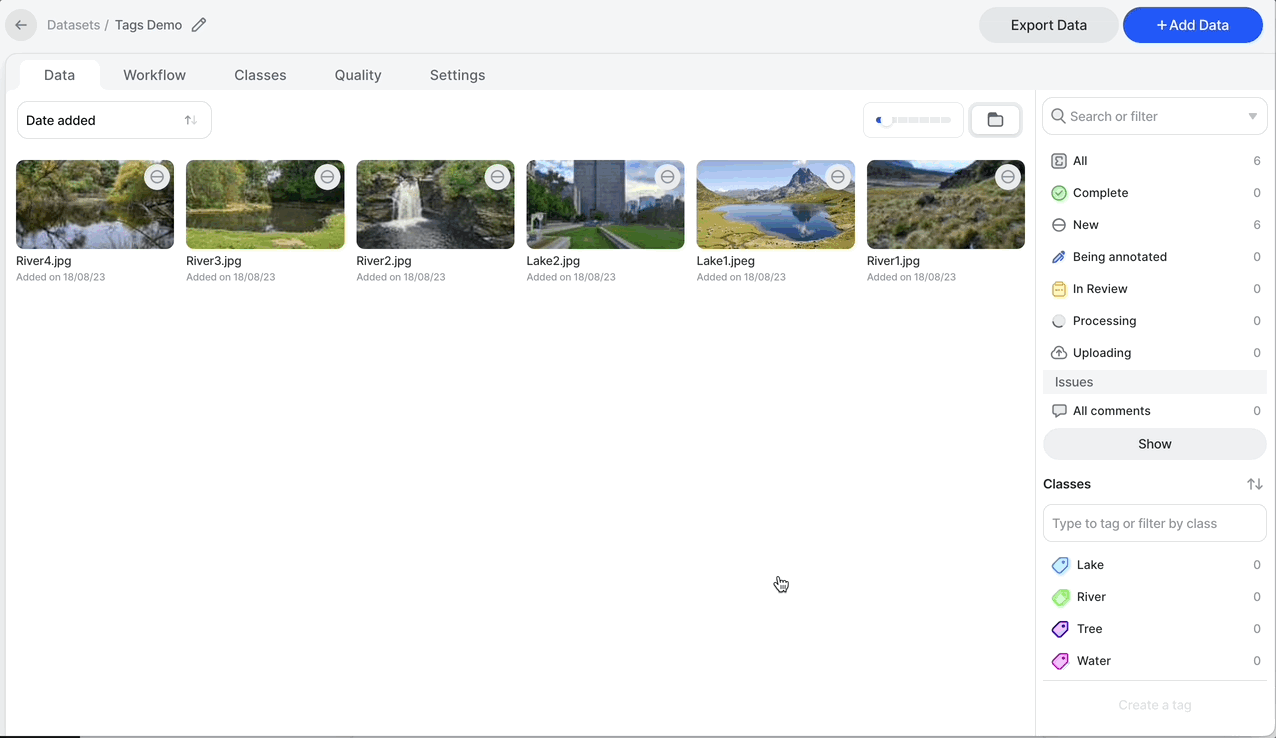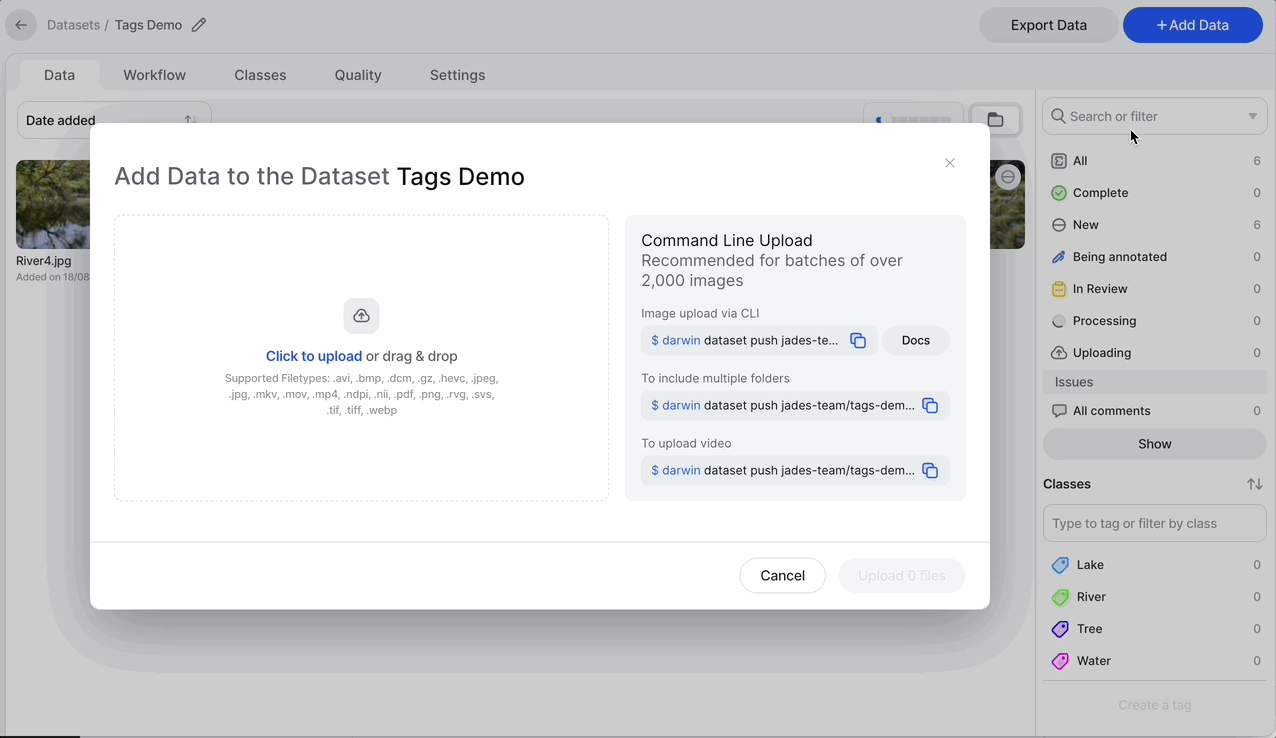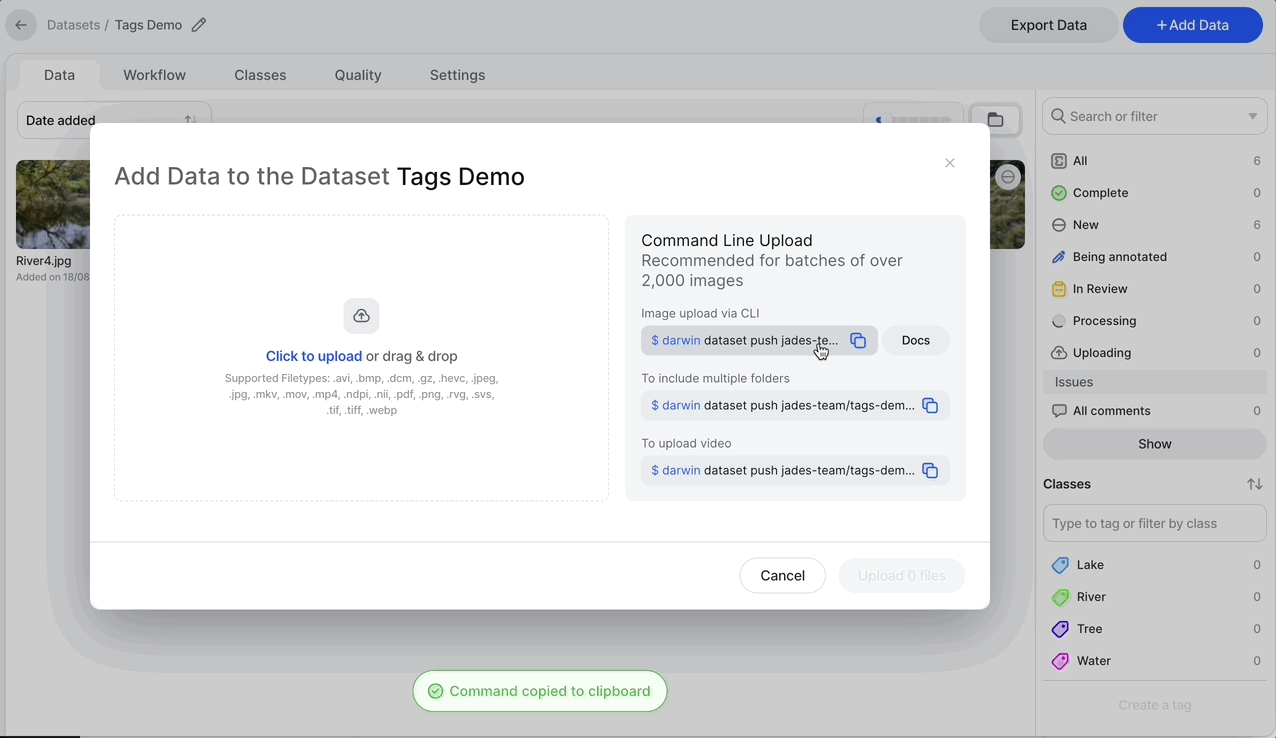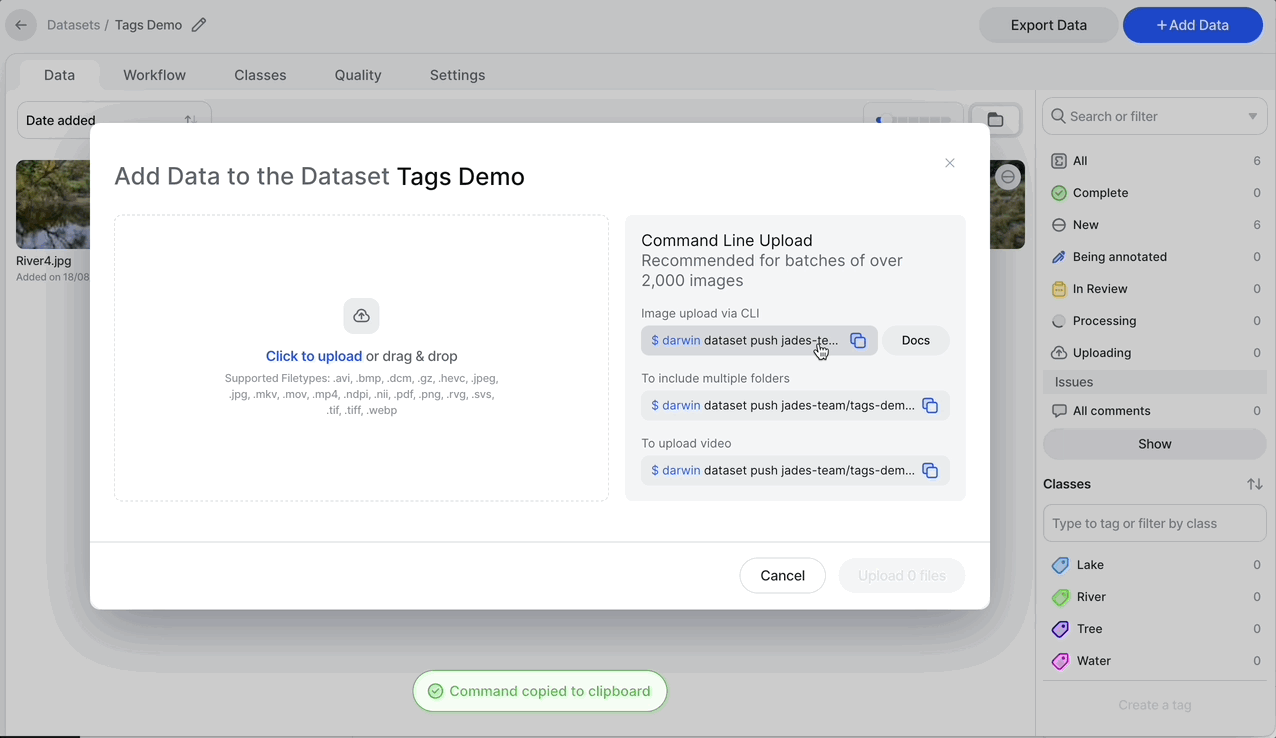
If you're uploading video files, you can specify the extraction rate by entering
--fps\<frame_rate>to the end of the path that command that V7 creates for you, the default fps being 2.
Replace /path/to/files/ with the actual path to the folder containing your saved files.
Press Enter one last time to start the upload process.
Updated 3 months ago
Next up
Now that you've imported data using CLI commands (and looked like a hacker doing it), you can use CLI commands to import annotations.